机器学习实战笔记
内容提要
- 聚焦监督学习,以结构化数据的预测问题为主
- 监督学习:y=f(x),gbdt,nn都是不同类型的f,深度学习就是其中的一类f,y叫label,x叫特征
- 分类问题:y是离散的,回归问题:y是连续的
- 结构化数据:每个数都有具体的物理意义
- 非结构化数据:图像、语音、nlp
- 强调共性问题,工作中需要注意的基本原则
- Reference
- 《Rules of Machine Learning》 — Google
(1.Rule与创造性之间的关系,rule更多的是原则 2.迁移学习)
工业界的机器学习
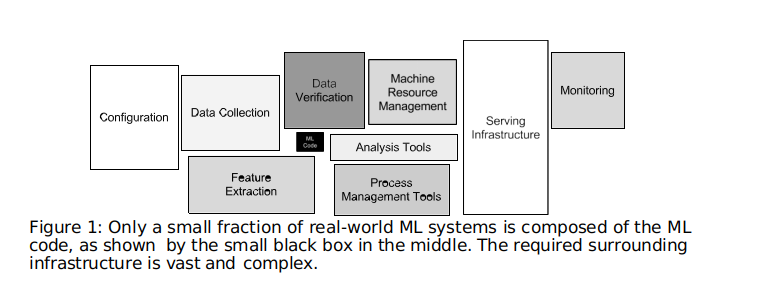
将机器学习落地的两个步骤
业务问题转化为机器学习问题,然后不断优化机器学习模型 (机器学习+运筹优化)
正确分析判断项目的价值
- 价值五角星(彼此可能会有影响)
- 开源(效果/用户体验):业务指标
- 节流(成本):存储、计算资源
- 效率:人效
- 安全:合规、隐私保护等
- 质量:可靠性、性能
- 预估/判断价值
(短信司机召回为例从效果上看,短信全发就是召回量的上限;支付方式默选,全部默选美团支付就是份额的上限;供需不平衡的计算资源优化)
对于新业务问题的处理方法
- 模型未动,规则先行。一方面积累线上数据,用于未来的模型训练,同时,也可以观测规则的收益,以此辅助判断模型的收益。
- 如果有通用的模型,也可以先用通用模型上线实验。
对于一个新业务问题第一个定制模型开发前的注意事项
- 明确业务目标,包括优化目标以及约束指标。
- 明确模型的评价标准,满足什么条件可以扩量,可以全量上线。
- 明确模型上线后,是否有方便的数据报表可以观测,通常重要的业务问题需要专门的报表支持。
- 明确模型的使用方式,是离线还是在线,如果是在线对于性能要求如何,控制模型的复杂度;是否需要阈值辅助解决,如果需要的话,阈值如何确定。
- 确保第一个模型要简单易用,目的是走通整个流程,一旦出现问题也方便debug。
- 通常一个新场景中第一个模型的收益是最大的。
- 要对该场景的数据做一些基础的EDA,帮助后面更好的进行样本和label的选择
- 要明确模型是一个分类问题、回归问题还是排序问题,并确定相应的线下评估指标。
- 分类:logloss,auc,fscore,gauc,KS
- 回归:mape,mae,rmse
- 排序:ndcg,map@k
训练样本的选择
- 所有的样本选择问题的核心就是线下训练用到的数据分布尽可能与线上场景保持一致
- 样本的bias问题
- 绝大多数场景中,线上数据都是有偏的,最典型的例子,信用风险的预测问题。
- 无偏样本是稀缺的,不同场景的无偏样本的成本不同,根据实际情况酌情采用。
- 有偏样本需要考虑如何debias。广告的位置偏差问题是这类问题的代表。
- 判断bias的严重性,越严重,无偏样本的收益越大。
- 样本的采样问题
- 时间与样本量的平衡。
- 正负样本的平衡,有的时候负样本未必是负样本,比如信息流推荐问题;对于催收预测问题,如果催一次就还了,在日志中只有一条记录,且是正样本,如果总催不还,一个人就存在多条负样本。
- 需要探查样本量的增加与模型预测能力的关系曲线
- 样本量与特征的关系,如果引入大量的离散特征,需要记着样本量也要跟上。如果是LR+L1正则进行特征选择,100w样本最终大概可以保留1w特征。
- 样本的清洗
- 由于埋点等工程问题,导致原始log出现问题。比如推荐了A权益,log中记录的是B权益
label的选择
- label的选择要尽可能与业务目标一致,往往越一致效果会越好。在有些场景下,label的选择会比特征、模型的优化收益更大,如:收银台默选促活场景。
- 选择label的时候,尽量找简单的、直接的、能够快速反馈的、可归因的
- 正例:点击、电话接通、使用没团支付完成订单
- 负例:用户满意度、30天激活率、90天逾期率。
- 对于确实存在反馈周期慢的业务指标,可以考虑使用代理指标提高反馈的效率,前提是要保证该指标与业务指标正相关。
- 对于比较不太直接的业务指标,也需要用代理指标替换。如:用户满意度 -> 点击率 or 在线时长。
- Label也要注意做数据清洗,避免工程问题导致的数据错误。
- 对于有些问题label需要人工标注的,需要严格把关标注质量
- 对于多个业务目标的问题,可以考虑使用多任务学习。
示例:美团支付默认-样本和label的选择
- 目标:订单转化率 & 美团支付份额
- 支付流程:用户提单 -> 选择支付方式 -> 支付成功(支付失败可能会重试并切换支付方式) -> 订单成功(订单流失)
- 方案演进:
- P(订单成功|默认美团支付) -> 美团份额提升不显著(订单成功不代表会用美团支付)
- P(订单成功|默认美团支付&最终使用美团支付) -> 总订单转化率+2bp、美团支付订单转化率-108bp、美团支付份额+61bp (漏了“使用美团支付失败后切换支付方式”这部分样本)
- P(最终使用美团支付&订单成功 |默认美团支付) -> 总订单转化率+10bp、美团支付订单转化率+341bp、美团支付份额+82bp
验证集与测试集的划分
- 大部分结构化数据的场景下,我们都要使用时序划分的方法。即:训练集、验证集、测试集在时间上是先后顺序。
- 可以使用k-fold的场景,如:声纹识别、意图识别等非结构化数据的场景。
- 通常验证集和测试集一旦确定,就尽量不动,方便新模型与过去模型做对比。如果要调整,最好也把老模型重新跑一遍,重新对齐。
特征挖掘的思路
- 数据本身限定了一个问题的天花板,模型和特征都是逼近天花板的方法
- 特征广义上分两个阶段:信息获取与信息提取,通常我们说的特征挖掘都是指的信息提取。
信息获取的思路
- 从业务出发,思考该场景下影响用户做出某种决策(label)的因素,通常决策越重,信息缺失就越厉害,这个时候信息获取的收益更大。如:电商广告的点击就比转化更容易,转化中可能需要参考竞对价格信息;催收工作中需要了解这个人在其他地方贷款情况。
- 从bad case中发现新的机会
信息提取的思路:通过数学的方法能够充分提取数据中蕴含的信息。
- 实时化与特征组合是两个关键方向
- 行为序列特征挖掘需要跟进
- 对于神经网模型,不用特别深入优化特征离散化的工作,往往分位数就还不错。
- 特征开发的时候可以按照主题设计,方便猴戏复用。
- 关键一问:xx特征当前模型是否已经学到了。
特征选择的方法
模型无关的特征选择
- 特征选择的方法如信息增益、缺失度、相关性等都是单特征的选择,只能用作参考
- 对某个特征进行随机扰动,观察模型预测能力下降的程度,以此作为模型权重的依据,这种方法会考虑到特征之间的相互作用相对更使用(确定模型特征权重的核心思想)
模型相关的特征选择
- LR+L1
- GBDT的特征权重,要看“gain”,而不是“split”
- NN的特征权重:看原始特征embedding层的L2范数 or 逐一shuffle特征,看预测结果的下降程度。
复杂模型的可解释性主要还是基于特征权重
避免建模过程中引入leak
- 如何判断模型中引入了leak
- 线下评估结果异常好
- 特征维度
- 特征生产过程中不要使用未来的数据,尤其是统计类特征
- 与label相关的统计特征尤其要小心,标准的target encoding是需要oof的。
- 样本维度
- 划分验证集合的时候没有按照时序划分,而是k-fold。
模型优化的思路
- 需要考虑模型更新的频率对于线上效果的影响
- 可以用树模型作为baseline,并通过树模型去判断特征的方向
- gbdt和nn应该能够解决监督学习的绝大部分问题,对于两种模型都应该有经验参数,在此基础上调整
- 深度学习模型的优势
- 在非结构化的问题泛化能力要明显好于结构化数据
- 类似非结构化的结构化数据:eta预估、交通流量预估、化学分子表达
- 大量id类特征,且更新频率:信息流、广告等
- 随着样本增多,模型的预测天花板更高。(待迭代认知)
- 对于结构化数据的问题,nn也主要通过引入更多信息拿到大部分收益。
- 同样的信息对于不同模型的输入会有区别,gbdt更适合连续特征,离散度高的需要进行特征提取。通过大量实验体会模型能学到哪些信息,学不到哪些信息,什么样的模式适合学哪些信息
模型上线前的注意事项
- 线下评测要比之前的模型好
- 线下和线上代码尽量保持一致,包括:特征提取、预处理、线上预测。
- 线下与线上的特征顺序保持一致
- 线上特征最好能够写到日志中,便于后续查错,如果不能全量写入,也可以考虑采样。
- 每两次实验中的diff尽量小,方便有效归因,确定后续方向。
- 做AA分析,了解当前场景下流量大小与线上稳定性的关系。
模型上线中要注意的问题
- 观察线上指标的抖动情况,确定模型的有效性
- 观察线上的变化是否符合预期
- 捕捉线上指标变化与线下指标的关系。如:线下提高多少,线上一定能有提升。
- 如果线上表现稳定,且与业务侧对齐后扩量继续观察。
- 正确(无论成败)的实验都是有价值的,错误(无论成败)的实验都是负价值的。
质量保障
- 模型管理SOP:待完善
- 事前
- 上线前,需要周知所有相关业务方
- 静默期不上线(静默期时间:周一至周四11:00-14:00和17:00-20:30;周五、周六和周日全天)
- 模型分为立刻运行模型(如默选模型)和窗口期运行模型(如催收模型),立刻运行模型在上线后保证半小时观测,窗口期运行模型在上线后的下一个运行期,需保证进行半小时观察(如运行不超过半小时,则观察全运行周期)
- 事中(算法工作尤其需要关注)
- 监控指标(业务指标、模型指标、特征相关指标)的配置和报警阈值
- 特征生成表要与上游强依赖,特征不更新的损失要比更新错的损失小
- 降级方案的制定
- 事后
- COE
线上线下不一致可能的原因
- 特征分布问题
- 可以用gbdt,用验证集和线上数据训练一个二分类模型,验证集样本为0,线上数据样本为1,根据二分类的准确度以及高权重的特征可以给出大致的分析结果
- 线下与线上特征提取的方法不一致
- 样本问题
- 忽略了样本偏置问题
- 指标问题
- 线下评估指标设置不合理。
反事实问题线下评估示例
- 权益分配问题:有三种权益,如何分配可以在成本约束情况下,收益最大
- 构建线下评估样本:对于集合$\gamma$随机发放权益,作为评估样本
- 基于训练好的策略A对评估样本进行预测,其中有1/3的样本是“事实”样本,可以准确计算收益。
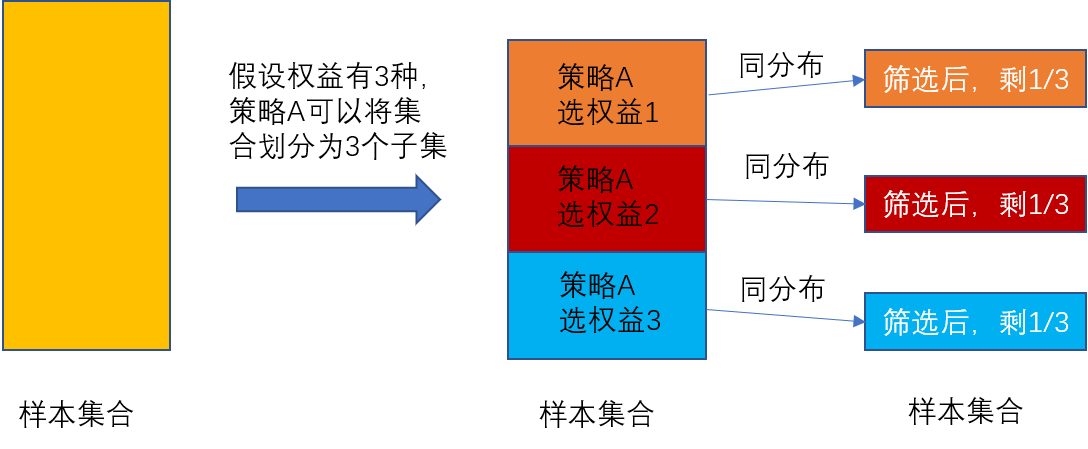
简单场景的优化思路
- 思考当前引入的信息是否还有缺失
- 对于已经引入的信息,是否充分表达。如:行为序列特征。
- 模型调参:nn的调参方差会更大一些
- 模型融合:尽量用最简单的方法,如线性加权,或者特征融合。比赛用的套路比如stacking,性价比低,且debug困难,随着单模型优化空间变小,该方法也逐步在工业界落地。
复杂系统的优化思路
- 将复杂系统拆解为多个子系统
- 分析每个子系统对于最终指标的影响(case分析)
- 针对子系统的ROI进行排序(技术难度x收益)
要建立自己的算法pipline
- 作为一门实践科学,高效实验是核心竞争力
- 合理把控实验节奏:上线计划、样本采集计划
- 机器不会休息
- 调参、特征提取、线下训练
如何入门
- 算法基本功
- 编程、数学、数据洞察
- 如果非要一个学习资料的话
- 李宏毅的机器学习视频(B站)
- 能动手尽量动作(All models are wrong but some are useful)
如何精进
- 能从纷繁复杂的各种资料中汲取知识是一门学问
- 养成paper reading的习惯,跟进学术圈的前沿进展(google系的paper泛化性更好)
- 跟进比赛圈的一些相关问题solution(kaggle)
- 跟进工业圈的一些分享(批判地看)
- 社交能力(重要)
- 批判的眼光看待各种问题,不要过拟合自己的经验,吃一堑长一智,其实是一种能力
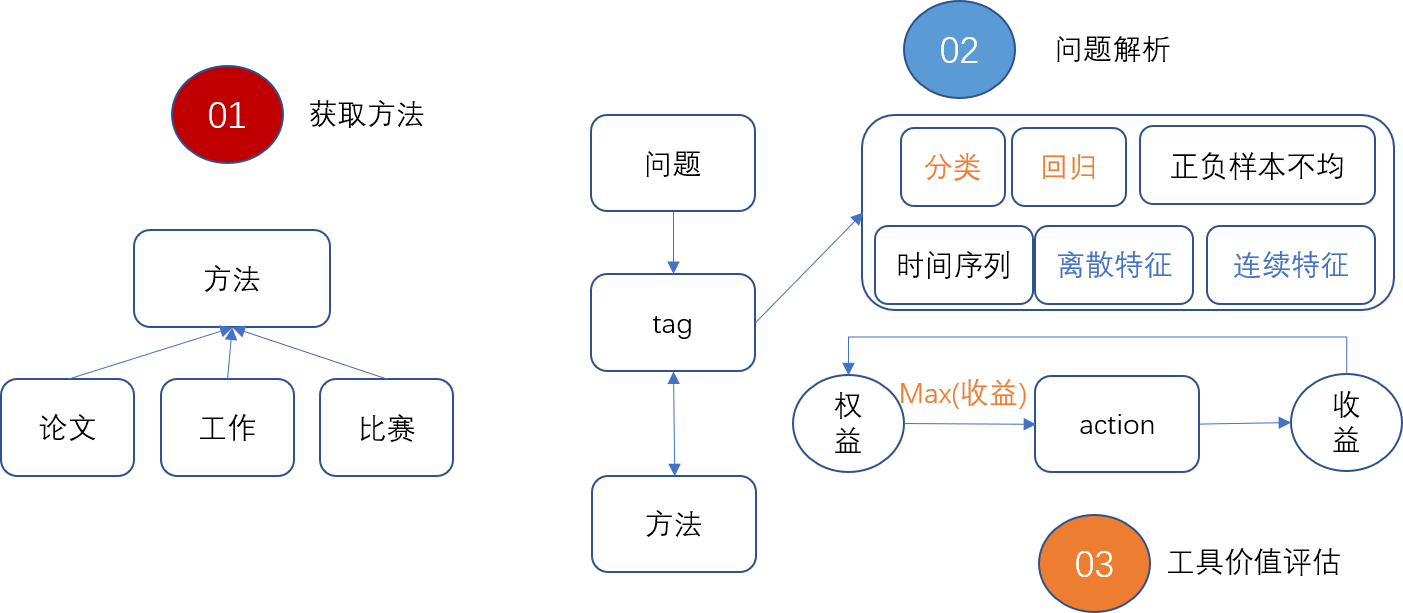
流程图




