一、产品形态与技术架构
1. 外卖首页列表产品形态
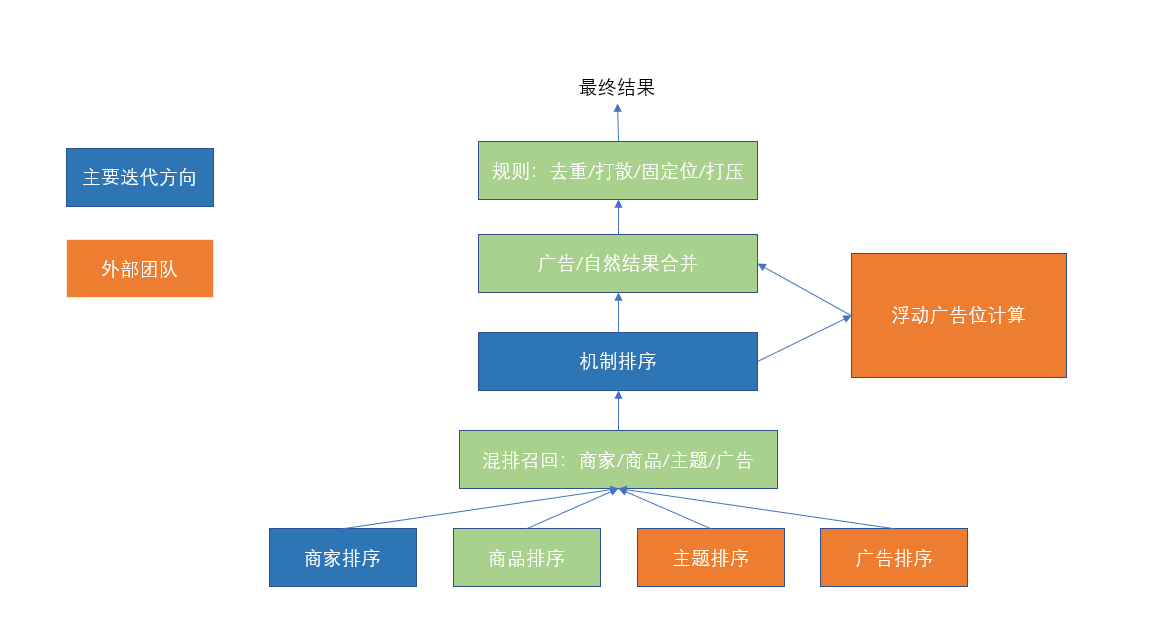
旧首页(2021.4以前)分为商家模式和菜品模式,新首页(2021.6以后)是混排瀑布流
- 目标
- 流量目标:UV_RPM(千人展示成交额)、UV_CXR(用户维度-转化率)、PV_CTR(卡片维度-点击率)
- 用户运营目标:心智、留存
- 商家运营目标:新店冷启动、品类扶持、KA商家扶持
- 元素
- 广告卡片:铂金广告、点金广告
- 自然流量卡片:商家卡片、商品卡片、主题卡片
2.混排服务架构
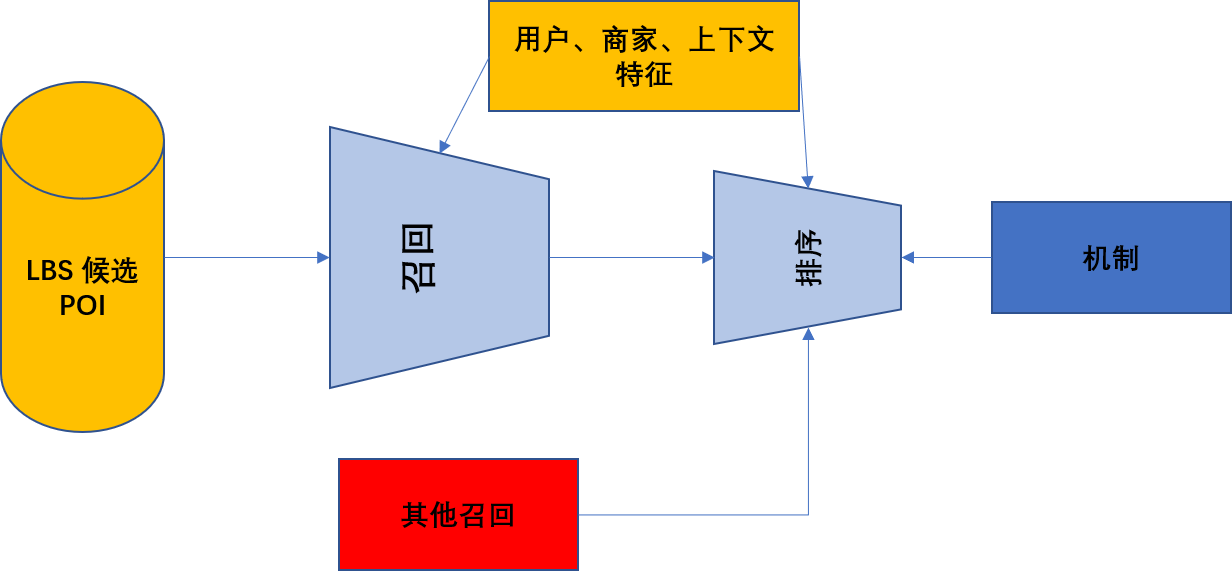
3. 商家排序服务架构
二、商家排序预估模型
1. 召回策略
主召回
- XGBoost树模型,对LBS商家打分
- 特征:数量30+,包括user特征、item特征(有限)user-item交叉特征、上下文特征
旁路召回
- 历史行为
- 实时行为
- 向量召回:基于向量相似度的i2i召回(trigger item:实时点击的商家,向量:word2vec训练、用户点击序列训练、同城负采样)
合并
- 各个旁路召回截断后插入至主召回头部,去重后整体截断200个
2. 精排模型演进路径

3. 精排策略:行为序列模型
- 实时点击序列+历史加购序列
- 商家表示:商家向量、商家名关键词、商家品类、主营菜品向量
- 上下文信息:小时差、停留时长、加购行为
- 序列内部的多样性
- 线上收益:PV_CTR + 1.23%
- 重点方向:
- 商家表示
- 上下文信息
- 序列抽取(长序列)
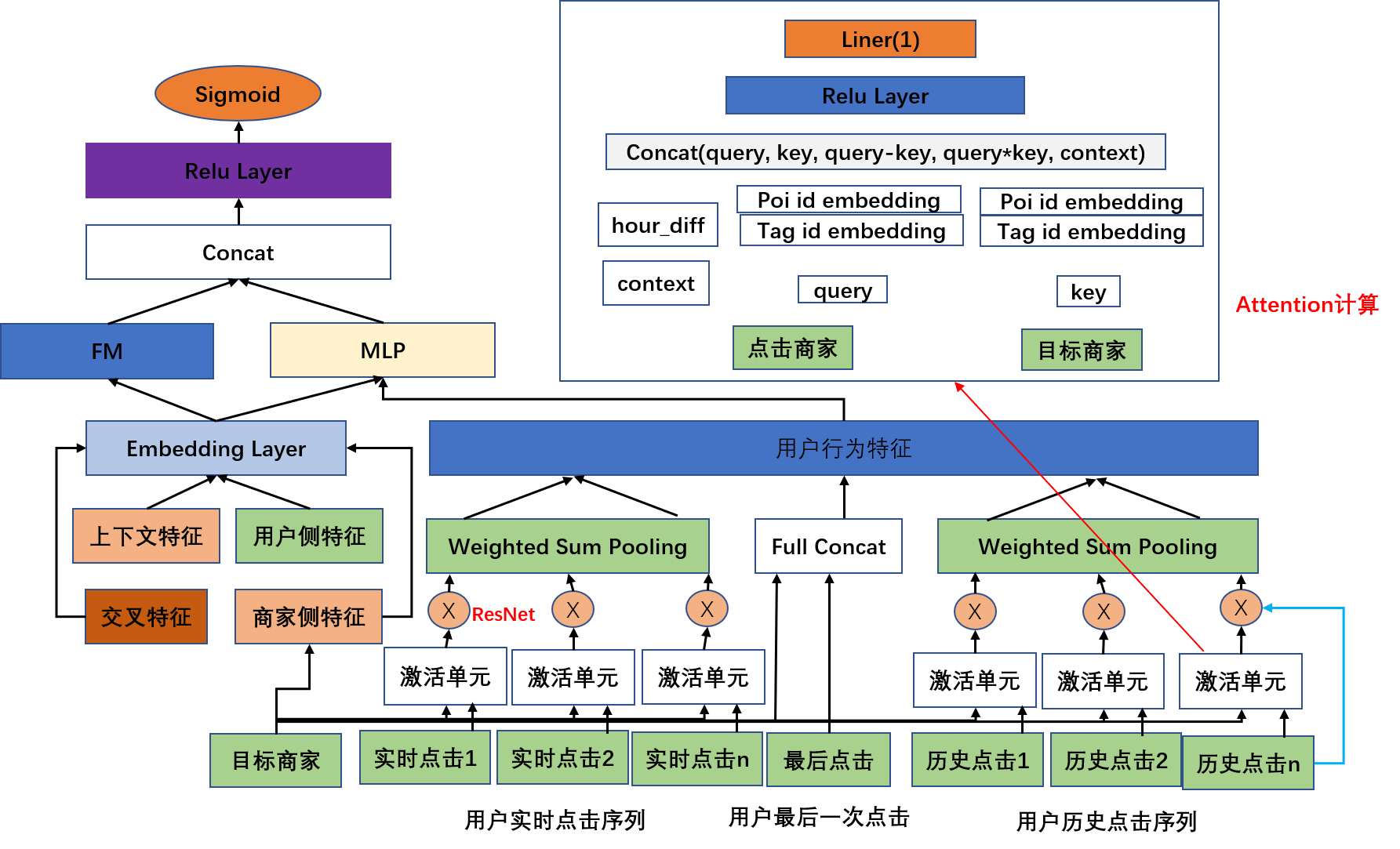
行为序列模型
4.精排策略:多任务学习
- PLE:Ctr和Cxr两个任务
- 不同目标损失函数的权重
- 等权重
- UWL(Uncertainty to Weigh Losses)
- 线上收益:PV_CTR+0.72%、UV_RPM+1.38%
- 收益来源:
- 多目标
- 多任务
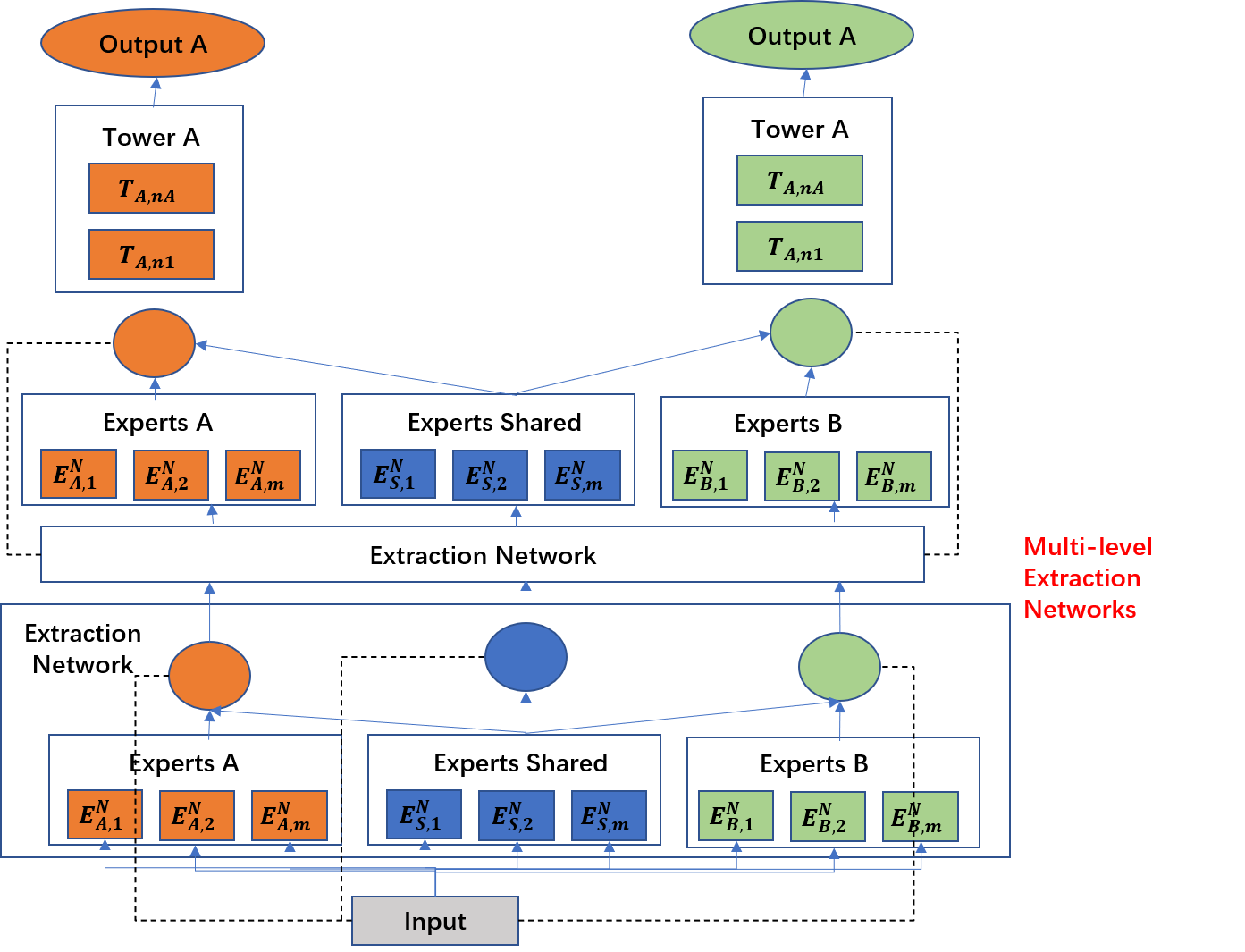
多任务学习
5. 精排策略:大模型
商家特征
- 商家ID
- 主要商品品类ID
用户特征
- 购买/点击/搜索的文本分词
- 用户-商家交叉特征
- 用户:购买/点击Top n商家品类、购买/点击top n商品类
- 商家:商家品类、主要商品品类
- 场景-商家交叉特征
- 场景:城市、小区/楼宇、地址类型、geohash、时段
- 2个月训练数据
三、机制层排序公式
1.机制层整体迭代路径

- 混排模型
- 输入精排预估的pCTR、pCXR以及其他相关特征,回归价值函数
- 价值函数:a click + b pay + c * 是否扶持
- 为什么从混排模型迁移到排序公式
- 未引入列表维度信息的情况下,二者等价(随机变量的期望)
- 迭代效率与敏感性
- 校准:分段线性校准,每天离线更新参数
2.排序公式:如何做流量扶持
- 假设按照pCXR排序,同时要给KA商家做流量扶持
- 方式1:常规商家公式pCXR,KA商家公式pCXR+0.01
- 公式2:常规商家公式pCXR,KA商家公式1.1 * pCXR
- 明确流量扶持的目的
- 保证扶持对象的曝光量:如主题卡片,带来展示形式的多样化,关注能否给用户曝光到,进而提升对主题场景的认知
- 保证扶持对象的订单量:如KA商家,保证重要客户的单量
- 问题建模其中i:第i个曝光位,I:全部曝光位集合;j:第j个候选,J(i):第i个曝光位下全部候选集合;$x_{ij}$:第i个曝光位是否曝光第j个候选,0-1变量;$C^{ka}_{order}$:KA的最少成单量。
3.排序公式:如何做流量扶持
结论:
- 保订单的扶持:常规商家公式$pCXR$,KA商家公式$(1 + a ISKA) pCXR$
- 保曝光的扶持:常规商家公式$pCXR$,KA商家公式$pCXR+a*ISKA$
简单例子
共2条请求,假设需要保证KA商家曝光(要求2条请求中至少一条曝光KA商家)
| 请求1 | 请求2 | |
|---|---|---|
| KA | 10 | 5 |
| 非KA | 18 | 10 |
a. 公式(1 + a * ISKA) * pCXR:调节系数到a=1.9即可曝光1次KA,总收益10+10
b. 公式pCXR+a* ISKA:调节系数到a=6即可曝光1次KA,总收益18+5
- 看待排序公式的视角:如何用最小的成本置换
- 单词请求视角:两种公式都是将KA的序往前提,不影响每种商家内部的序
- 全局视角:公式的形式会决定哪些请求适合曝光KA,或者将KA的曝光/订单需求分配到哪些请求
- 线上效果:目标是扶持曝光,曝光扶持公式 vs 订单扶持公式UV_CXR+0.66%,PV_CTR+0.17%
4.排序公式:多目标
加法公式 vs 乘法公式
- 举例:均衡PVCTR、PVCXR两个目标的时候,以下两个公式哪个好?排序公式1:$apCTR + b pCXR$;排序公式2:$pCTR^{a}*pCXR^{b}$
目标分解到每个曝光位
什么样的目标是帕累托最优?
- 两个目标相加是帕累托最优:$a PVCTR + b PVCXR = a \sum(pCTR) + b \sum(pCXR) = \sum(a pCTR + b pCXR)$
- 两个目标相乘帕累托最优:$PVCTR^{a} PVCXR^{b} = [\sum(pCTR)]^{a} [\sum(pCXR)]^b$,乘法目标的情况下不可进一步分解。
分场景个性化调节系数a,b是否有空间?
- 比如高峰期时间段增大pCXR系数,其他时间段增加pCTR系数
简单例子
两个请求,每个请求内:从两个候选中选择一个曝光
| pCTR | pCXR | ||
| 请求1 | 候选1 | 4 | 1 |
| 候选2 | 2.1 | 2.1 | |
| 请求2 | 候选1 | 1 | 4 |
| 候选2 | 2.1 | 2.1 |
a. 公式pCTR + pCXR:两次请求都选择候选1,pCTR总收益5,pCXR总收益为5
b. 公式pCTR*pCXR:两次请求都选择候选2,pCTR总收益4.2,pCXR总收益为4.2
模拟实验:画图(alpha metricA + metricB 优于 power(metricA, alpha) metricB)
线上收益:加法 vs 乘法,UV_CXR+0.60%,PV_CTR+0.15%
5.排序公式:目标不可分
- 什么目标不可分:难以直接建模
- 列表维度的指标:UVCXR等
- 全局入口下的指标
- From 模型做预估 to 模型做决策
- 原因:解空间爆炸
- 参数搜索:ES、CEM、强化学习
- 方案介绍
- State:用户特征、上下文特征
- Action:排序公式的参数
- Reward:列表维度的权益(也可以从全局入口归因label)
- 先在线上随机做action,收集数据,学习critic网络(输入state、action、输出reward)
- 接下来固定actor网络参数,学习actor网络(输入state,输出action)
四、总结与思考
- 总结-收益分析
- 用户兴趣建模
- 多任务学习
- 大模型
- 混排模型/排序公式
- 思考
- 对上界的分析
- 化繁为简
- 保持认知迭代




