线程池及其原理
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。使用线程池可以有效地控制系统中并发线程的数量。
当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
线程池的使用
线程池的基类是concurrent.futures模块中的Executor,Executor提供了两个子类,即 ThreadPoolExecutor 和ProcessPoolExecutor,其中ThreadPoolExecutor用于创建线程池,而ProcessPoolExecutor用于创建进程池。使用线程池/进程池来管理并发编程,那么只要将相应的task函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定。常用的方法如下:
- submit(fn, args, **kwargs):将 fn 函数提交给线程池。args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。
- map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数
- map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
- shutdown(wait=True):关闭线程池。
程序将task函数提交(submit)给线程池后,submit方法会返回一个Future对象,Future类主要用于获取线程任务函数的返回值。由于线程任务会在新线程中以异步方式执行,因此,线程执行的函数相当于一个“将来完成”的任务,所以 Python使用Future来代表。提供的方法如下:
- cancel():取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。
- cancelled():返回 Future 代表的线程任务是否被成功取消。
- running():如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。
- done():如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True。
- result(timeout=None):获取该 Future代表的线程任务最后返回的结果。如果Future代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout参数指定最多阻塞多少秒。
- exception(timeout=None):获取该 Future 代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回 None。
- add_done_callback(fn):为该 Future代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该fn函数。
在用完一个线程池后,应该调用该线程池的shutdown()方法,该方法将启动线程池的关闭序列。调用shutdown()方法后的线程池不再接收新任务,但会将以前所有的已提交任务执行完成。当线程池中的所有任务都执行完成后,该线程池中的所有线程都会死亡。执行线程任务的步骤如下:
- 调用ThreadPoolExecutor类的构造器创建一个线程池
- 定义一个普通函数作为线程任务
- 调用ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
- 当不想提交任何任务时,调用 ThreadPoolExecutor对象的 shutdown() 方法来关闭线程池。
使用线程池执行线程任务如下:
from concurrent.futures import ThreadPoolExecutor
import threading
import time
def action(max): # 准备作为线程任务的函数
my_sum = 0
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
my_sum += i
return my_sum
pool = ThreadPoolExecutor(max_workers=2) # 2条线程的线程池
future1 = pool.submit(action, 50) # 提交一个task,50为action函数
future2 = pool.submit(action, 100)
print(future1.done())
time.sleep(3)
print(future2.done())
# 查看结果
print(future1.result(), future2.result())
# 关闭线程池
pool.shutdown()
'''
...
ThreadPoolExecutor-0_1 95
ThreadPoolExecutor-0_1 96
ThreadPoolExecutor-0_1 97
ThreadPoolExecutor-0_1 98
ThreadPoolExecutor-0_1 99
True
1225 4950
'''
获取执行结果
程序调用了Future的result()方法来获取线程任务的运回值,但该方法会阻塞当前主线程,只有等到钱程任务完成后,result()方法的阻塞才会被解除。如果程序不希望直接调用result()方法阻塞线程,则可通过Future的 add_done_callback()方法来添加回调函数,该回调函数形如fn(future)。当线程任务完成后,程序会自动触发该回调函数,并将对应的Future对象作为参数传给该回调函数。
from concurrent.futures import ThreadPoolExecutor
import threading
import time
def action(max):
my_sum = 0
for i in range(max):
print(threading.currentThread().name + ' ' + str(i))
my_sum += i
return my_sum
# 创建2条线程的线程池
with ThreadPoolExecutor(max_workers=2) as pool:
future1 = pool.submit(action, 50)
future2 = pool.submit(action, 100)
def get_result(future):
print(future.result())
# 添加线程回调函数
future1.add_done_callback(get_result)
future2.add_done_callback(get_result)
print('-----------')
分别为future1、future2添加回调函数,该回调函数在线程任务结束时获取其返回值。因此主线程不会被阻塞,可以立即看到输出主线程打印出的横线。接下来将会看到两个新线程并发执行,当线程任务执行完成后,get_result()函数被触发,输出线程任务的返回值。Exectuor提供了map(func, *iterables, timeout=None, chunksize=1)方法,会为iterables的每个元素启动一个线程,并发执行func函数。这种方式相当于启动len(iterables)个线程,井收集每个线程的执行结果。
with ThreadPoolExecutor(max_workers=4) as pool:
# 使用线程执行map计算
# 后面元组有3个元素,因此程序启动3条线程来执行action函数
results = pool.map(action, (50, 100, 150))
print('--------------')
for r in results:
print(r)
程序的线程池包含4个线程,如果继续使用只包含两个线程的线程池,此时将有一个任务处于等待状态,必须等其中一个任务完成,线程空闲出来才会获得执行的机会),map()方法的返回值将会收集每个线程任务的返回结果。虽然程序会以并发方式来执行action()函数,但最后收集的action()函数的执行结果,依然与传入参数的结果保持一致。也就是说,上面results的第一个元素是action(50)的结果,第二个元素是action(100) 的结果,第三个元素是action(150) 的结果。
threading Local()函数:返回线程局部变量
除非必须将多线程使用的资源设置为公共资源,Python threading 模块还提供了一种可彻底避免数据不同步问题的方法,即本节要介绍的 local() 函数。
使用local()函数创建的变量,可以被各个线程调用,但和公共资源不同,各个线程在使用local()函数创建的变量时,都会在该线程自己的内存空间中拷贝一份。这意味着,local()函数创建的变量看似全局变量(可以被各个线程调用),但各线程调用的都是该变量的副本(各调用各的,之间并无关系)。使用 threading模块中的local()函数,可以为各个线程创建完全属于它们自己的变量(又称线程局部变量)。正是由于各个线程操作的是属于自己的变量,该资源属于各个线程的私有资源,因此可以从根本上杜绝发生数据同步问题。用local()函数的好处,至少有以下2点:
- 各个线程操作的都是自己的私有资源,不会涉及到数据同步问题;
- 由于local()函数的返回值位于全局作用域,无论在程序什么位置,都可以随时调用,很方便。
与互斥锁的区别
无论是使用线程局部变量,还是使用互斥锁机制,其根本目的是为了解决多线程访问公共资源时可能发生的数据同步问题。互斥锁机制实现的出发点是,在各线程仍使用公共资源的前提下,想办法控制各个线程对该资源的同时访问;而线程局部变量则另辟蹊径,直接令多线程操作各自的私有资源,从根本上杜绝了同时访问所带来的数据同步问题。
需要说明的一点是,线程局部变量的解决方案,并不能完全替代互斥锁同步机制。同步机制是为了同步多个线程对公共资源的并发访问,是多个线程之间进行通信的有效方式;而线程局部变量则从根本上避免了多个钱程之间对共享资源(变量)的竞争。如果多线程之间需要共享资源(如多人操作同一银行账户的例子),就使用互斥锁同步机制;反之,如果仅是为了解决多线程之间的共享资源冲突,则推荐使用线程局部变量。
Timer定时器:控制函数在特定时间执行
# 每1s输出一次当前时间
from threading import Timer
import time
# 定义总共输出几次的计数器
count = 0
def print_time():
print("当前时间:%s" % time.ctime())
global t, count
count += 1
# 如果count小于10,开始下一次调度
if count < 10:
t = Timer(1, print_time)
t.start()
# 指定1秒后执行print_time函数
t = Timer(1, print_time)
t.start()
'''
当前时间:Sat May 2 20:32:07 2020
当前时间:Sat May 2 20:32:08 2020
当前时间:Sat May 2 20:32:09 2020
当前时间:Sat May 2 20:32:10 2020
当前时间:Sat May 2 20:32:11 2020
当前时间:Sat May 2 20:32:12 2020
当前时间:Sat May 2 20:32:13 2020
当前时间:Sat May 2 20:32:14 2020
当前时间:Sat May 2 20:32:15 2020
当前时间:Sat May 2 20:32:16 2020
'''
schedule任务调度及用法
Python 还提供有一个更强大的、可用来定义执行任务调度的 sched 模块,该模块中含有一个 scheduler 类,可用来执行更复杂的任务调度。
scheduler类常用的构造方法如下:
scheduler(timefunc=time.monotonic, delayfunc=time.sleep)
可以向该构造方法中传入 2 个参数(当然也可以不提供,因为都有默认值),分别表示的含义如下:
- timefunc:指定生成时间戳的函数,默认使用time.monotonic来生成时间戳;
- delayfunc:在未到达指定时间前,通过该参数可以指定阻塞任务执行的函数,默认采用time.sleep()函数来阻塞程序。
scheduler类中提供常用的方法有:
| 方法格式 | 功能 |
| ———————————————————————————————— | ——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————- |
| scheduler.enter(delay, priority, action, argument=(), kwargs={}) | 在 time 规定的时间后,执行 action 参数指定的函数,其中 argument 和 kwargs 负责为 action 指定的函数传参,priority 参数执行要执行任务的等级,当同一时间点有多个任务需要执行时,等级越高( priority 值越小)的任务会优先执行。该函数会返回一个 event,可用来取消该任务。 |
| scheduler.cancel(event) | 取消 event 任务。注意,如果 event 参数执行的任务不存在,则会引发 ValueError 错误。 |
| scheduler.run(blocking=True) | 运行所有需要调度的任务。如果调用该方法的 blocking 参数为 True,该方法将会阻塞线程,直到所有被调度的任务都执行完成。 |
scheduler类的实例如下:
import threading
from sched import scheduler
def action(arg):
print(arg)
#定义线程要调用的方法,*add可接收多个以非关键字方式传入的参数
def thread_action(*add):
#创建任务调度对象
sche = scheduler()
#定义优先级
i = 3
for arc in add:
# 指定1秒后执行action函数
sche.enter(1, i, action, argument=(arc, ))
i = i - 1
#执行所有调度的任务
sche.run()
#定义为线程方法传入的参数
my_tuple = ("http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/java/")
#创建线程
thread = threading.Thread(target=thread_action, args=my_tuple)
#启动线程
thread.start()
'''
http://c.biancheng.net/java/
http://c.biancheng.net/shell/
http://c.biancheng.net/python/
'''
os.fork()方法:创建新进程
每个 Python 程序在执行时,系统都会生成一个新的进程,该进程又称父进程(或主进程)。在此基础上,Python os 模块还提供有 fork() 函数,该函数可以在当前程序中再创建出一个进程(又称子进程)。
也就是说,程序中通过引入 os 模块,并调用其提供的 fork() 函数,程序中会拥有 2 个进程,其中父进程负责执行整个程序代码,而通过 fork() 函数创建出的子进程,会从创建位置开始,执行后续所有的程序(包含创建子进程的代码)。语法格式:
pid = os.fork()
其中,pid作为函数的返回值,主进程和子进程都会执行该语句,但主进程执行 fork()函数得到的pid值为非 0 值(其实是子进程的进程ID),而子进程执行该语句得到的pid值为0。因此,pid常常作为区分父进程和子进程的标志。os模块提供了getpid()和getppid()函数,可分别用来获取当前进程的ID号和父进程的ID号。
注意,os.fork() 函数在 Windows 系统上无效,只在 UNIX 及类 UNIX 系统上(包括UNIX、Linux 和 Mac OS X)效。
import os
print('父进程 ID=', os.getpid())
# 子进程
pid = os.fork()
print('当前进程 ID =',os.getpid()," pid=",pid)
#根据 pid 值,分别为子进程和父进程布置任务
if pid == 0:
print('子进程, ID=',os.getpid()," 父进程 ID=",os.getppid())
else:
print('父进程, ID=',os.getpid()," pid=",pid)
'''
父进程 ID= 23633
当前进程 ID = 23633 pid= 23634
父进程, ID= 23633 pid= 23634
当前进程 ID = 23634 pid= 0
子进程, ID= 23634 父进程 ID= 23633
'''
Process创建进程
Python multiprocessing 模块提供了 Process 类,该类可用来在 Windows 平台上创建新进程。和使用 Thread 类创建多线程方法类似,使用 Process 类创建多进程也有以下 2 种方式:
- 直接创建Process类的实例对象,由此就可以创建一个新的进程;
- 通过继承Process类的子类,创建实例对象,也可以创建新的进程。注意,继承Process类的子类需重写父类的 run()方法。
| 属性名或方法名 | 功能 |
|---|---|
| run() | 第2种创建进程的方式需要用到,继承类中需要对方法进行重写,该方法中包含的是新进程要执行的代码。 |
| start() | 和启动子线程一样,新创建的进程也需要手动启动,该方法的功能就是启动新创建的线程。 |
| join([timeout]) | 和thread类 join() 方法的用法类似,其功能是在多进程执行过程,其他进程必须等到调用 join() 方法的进程执行完毕(或者执行规定的 timeout 时间)后,才能继续执行; |
| is_alive() | 判断当前进程是否还活着。 |
| terminate() | 中断该进程。 |
| name属性 | 可以为该进程重命名,也可以获得该进程的名称。 |
| daemon | 和守护线程类似,通过设置该属性为 True,可将新建进程设置为“守护进程”。 |
| pid | 返回进程的 ID 号。大多数操作系统都会为每个进程配备唯一的 ID 号。 |
通过Process类创建进程
使用 Process 类创建实例化对象,其本质是调用该类的构造方法创建新进程。Process 类的构造方法格式如下:
def init(self,group=None,target=None,name=None,args=(),kwargs={})
其中,各个参数的含义为:
- group:该参数未进行实现,不需要传参;
- target:为新建进程指定执行任务,也就是指定一个函数;
- name:为新建进程设置名称;
- args:为 target 参数指定的参数传递非关键字参数;
- kwargs:为 target 参数指定的参数传递关键字参数。
from multiprocessing import Process
import os
print("当前进程ID:", os.getpid())
# 定义一个函数,准备作为新进程的 target 参数
def action(name, *add):
print(name)
for arc in add:
print("%s --当前进程%d" % (arc, os.getpid()))
if __name__ == '__main__':
#定义为进程方法传入的参数
my_tuple = ("http://forwardpeng.club/python/",\
"http://forwardpeng.club/shell/",\
"http://forwardpeng.club/java/")
#创建子进程,执行 action() 函数
my_process = Process(target=action, args=("my_process进程", *my_tuple))
#启动子进程
my_process.start()
#主进程执行该函数
action("主进程", *my_tuple)
'''
当前进程ID: 24176
主进程
http://forwardpeng.club/python/ --当前进程24176
http://forwardpeng.club/shell/ --当前进程24176
http://forwardpeng.club/java/ --当前进程24176
my_process进程
http://forwardpeng.club/python/ --当前进程24177
http://forwardpeng.club/shell/ --当前进程24177
http://forwardpeng.club/java/ --当前进程24177
'''
通过Process继承类创建进程
除了直接使用 Process 类创建进程,还可以通过创建 Process 的子类来创建进程。需要注意的是,在创建 Process 的子类时,需在子类内容重写run()方法。实际上,该方法所起到的作用,就如同第一种创建方式中target参数执行的函数。
另外,通过 Process 子类创建进程,和使用 Process 类一样,先创建该类的实例对象,然后调用 start() 方法启动该进程。下面程序演示如何通过 Process 子类创建一个进程。
进程启动的3中方法
启动进程的方式大致可分为以下 3 种:
- spawn:使用此方式启动的进程,只会执行和 target 参数或者 run() 方法相关的代码。Windows 平台只能使用此方法,事实上该平台默认使用的也是该启动方式。相比其他两种方式,此方式启动进程的效率最低。
- fork:使用此方式启动的进程,基本等同于主进程(即主进程拥有的资源,该子进程全都有)。因此,该子进程会从创建位置起,和主进程一样执行程序中的代码。注意,此启动方式仅适用于UNIX平台,os.fork()创建的进程就是采用此方式启动的。
- forserver:使用此方式,程序将会启动一个服务器进程。即当程序每次请求启动新进程时,父进程都会连接到该服务器进程,请求由服务器进程来创建新进程。通过这种方式启动的进程不需要从父进程继承资源。注意,此启动方式只在 UNIX平台上有效。
multiprocessing.set_start_method('spawn')
#创建子进程,执行 action() 函数
my_process = multiprocessing.Process(target = action, args = ("my_process进程",*my_tuple))
###############
ctx = multiprocessing.get_context('spawn')
#用 ctx 代替 multiprocessing 模块创建子进程,执行 action() 函数
my_process = ctx.Process(target = action, args = ("my_process进程",*my_tuple))
multiprocessing 模块提供的 get_context() 函数来设置进程启动的方法,调用该函数时可传入 “spawn”、”fork”、”forkserver” 作为参数,用来指定进程启动的方式,需用该函数的返回值,代替 multiprocessing模块调用Process()。
多进程编程和多线程编程优缺点
多进程编程和多钱程编程,都可以使用并行机制来提升系统的运行效率。二者的区别在于运行时所占的内存分布不同,多钱程是共用一套内存的代码块区间;而多进程是各用一套独立的内存区间。
多进程编程也有不足,即创建进程的代价非常大,因为操作系统要给每个进程分配固定的资源,并且操作系统对进程的总数会有一定的限制,若进程过多,操作系统调度都会存在问题,会造成假死状态。多线程编程的优点是效率较高一些,适用于批处理任务等功能;不足之处在于,任何一个线程崩溃都可能造成整个进程的崩溃,因为它们共享了进程的内存资源池。
既然多线程编程和多进程编程各有优缺点,因此它们分别适用于不同的场景。比如说,对于计算密集型的任务,多进程效率会更高一下;而对于IO密集型的任务(比如文件操作,网络爬虫),采用多线程编程效率更高。
对于任务数来说,无论是多进程编程或者多线程编程,其进程数或线程数都不能太多:
- 对于多进程编程来说,操作系统在切换任务时,会有一系列的保护现场措施,这要花费相当多的系统资源,若任务过多,则大部分资源都被用做干这些了,结果就是所有任务都做不好;
- 多线程编程也不是线程个数越多效率越高,通过下面的公式可以计算出线程数量最优的一个参考值。
进程池管理进程
进程池可以提供指定数量的进程给用户使用,即当有新的请求提交到进程池中时,如果池未满,则会创建一个新的进程用来执行该请求;反之,如果池中的进程数已经达到规定最大值,那么该请求就会等待,只要池中有进程空闲下来,该请求就能得到执行。Python multiprocessing 模块提供了 Pool() 函数,专门用来创建一个进程池,该函数的语法格式如下:
multiprocessing.Pool( processes )
其中,processes 参数用于指定该进程池中包含的进程数。如果进程是 None,则默认使用 os.cpu_count() 返回的数字(根据本地的 cpu 个数决定,processes 小于等于本地的 cpu 个数)。注意,Pool() 函数只是用来创建进程池,而 multiprocessing 模块中表示进程池的类是 multiprocessing.pool.Pool 类。该类中提供了一些和操作进程池相关的方法,如下表所示。
| 方法名 | 功能 |
| ——————————————————————————————————— | —————————————————————————————————————————————————————————————————————— |
| apply( func[, args[, kwds]] ) | 将 func 函数提交给进程池处理。其中 args 代表传给 func 的位置参数,kwds 代表传给 func 的关键字参数。该方法会被阻塞直到 func 函数执行完成。 |
| apply_async( func[, args[, kwds[, callback[, error_callback]]]] ) | 这是 apply() 方法的异步版本,该方法不会被阻塞。其中 callback 指定 func 函数完成后的回调函数,error_callback 指定 func 函数出错后的回调函数。 |
| map( func, iterable[, chunksize] ) | 类似于 Python 的 map() 全局函数,只不过此处使用新进程对 iterable 的每一个元素执行 func 函数。 |
| map_async( func, iterable[, chunksize[, callback[, error_callback]]] ) | 这是 map() 方法的异步版本,该方法不会被阻塞。其中 callback 指定 func 函数完成后的回调函数,error_callback 指定 func 函数出错后的回调函数。 |
| imap( func, iterable[, chunksize] ) | 这是 map() 方法的延迟版本。 |
| imap_unordered( func, iterable[, chunksize] ) | 功能类似于 imap() 方法,但该方法不能保证所生成的结果(包含多个元素)与原 iterable 中的元素顺序一致。 |
| starmap( func, iterable[,chunksize] ) | 功能类似于 map() 方法,但该方法要求 iterable 的元素也是 iterable 对象,程序会将每一个元素解包之后作为 func 函数的参数。 |
| close() | 关闭进程池。在调用该方法之后,该进程池不能再接收新任务,它会把当前进程池中的所有任务执行完成后再关闭自己。 |
| terminate() | 立即中止进程池。 |
| join() | 等待所有进程完成。 |
进程间通信的实现方法(Queue和Pipe)
Python 也提供了多种实现进程间通信的机制,主要有以下 2 种:
- Python multiprocessing 模块下的 Queue 类,提供了多个进程之间实现通信的诸多方法;
- Pipe,又被称为“管道”,常用于实现 2 个进程之间的通信,这 2 个进程分别位于管道的两端。
Queue实现进程间通信
实现进程间通信,需要使用 multiprocessing 模块中的 Queue 类。原理是使用了操作系统给开辟的一个队列空间,各个进程可以把数据放到该队列中,当然也可以从队列中把自己需要的信息取走。Queue类常用方法有:
| 方法名 | 功能 |
| —————————————————————- | ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— |
| put( obj[ ,block=True [ ,timeout=None ] ] ) | 将 obj 放入队列,其中当 block 参数设为 True 时,一旦队列被写满,则代码就会被阻塞,直到有进程取走数据并腾出空间供 obj 使用。timeout 参数用来设置阻塞的时间,即程序最多在阻塞 timeout 秒之后,如果还是没有空闲空间,则程序会抛出 queue.Full 异常。 |
| put_nowait(obj) | 该方法的功能等同于 put(obj, False)。 |
| get([block=True , [timeout=None] ]) | 从队列中取数据并返回,当 block 为 True 且 timeout 为 None 时,该方法会阻塞当前进程,直到队列中有可用的数据。如果 block 设为 False,则进程会直接做取数据的操作,如果取数据失败,则抛出 queue.Empty 异常(这种情形下 timeout 参数将不起作用)。如果手动 timeout 秒数,则当前进程最多被阻塞 timeout 秒,如果到时依旧没有可用的数据取出,则会抛出 queue.Empty 异常。 |
| get_nowait() | 该方法的功能等同于 get(False)。 |
| empty() | 判断当前队列空间是否为空,如果为空,则该方法返回 True;反之,返回 False。 |
import multiprocessing
def processFun(queue, name):
print(multiprocessing.current_process().pid, "进程放数据:", name)
#将 name 放入队列
queue.put(name)
if __name__ == '__main__':
# 创建进程通信的Queue
queue = multiprocessing.Queue()
# 创建子进程
process = multiprocessing.Process(target=processFun,
args=(queue,
"http://forwardpeng.club/python/"))
# 启动子进程
process.start()
#该子进程必须先执行完毕
process.join()
print(multiprocessing.current_process().pid, "取数据:")
print(queue.get())
'''
25487 进程放数据: http://forwardpeng.club/python/
25486 取数据:
http://forwardpeng.club/python/
'''
Pipe实现进程通信
Pipe 也常用来实现 2 个进程之间的通信,这 2 个进程分别位于管道的两端,一端用来发送数据,另一端用来接收数据。使用Pipe 实现进程通信,首先需要调用 multiprocessing.Pipe() 函数来创建一个管道。该函数的语法格式如下:
conn1, conn2 = multiprocessing.Pipe( [duplex=True] )
其中,conn1 和 conn2 分别用来接收 Pipe 函数返回的 2 个端口;duplex 参数默认为 True,表示该管道是双向的,即位于 2 个端口的进程既可以发送数据,也可以接受数据,而如果将 duplex 值设为 False,则表示管道是单向的,conn1 只能用来接收数据,而 conn2 只能用来发送数据。
conn1 和 conn2 都属于 PipeConnection 对象,它们还可以调用下表所示的这些方法。
| 方法名 | 功能 |
| —————————————————— | —————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————- |
| send(obj) | 发送一个 obj 给管道的另一端,另一端使用 recv() 方法接收。需要说明的是,该 obj 必须是可序列化的,如果该对象序列化之后超过 32MB,则很可能会引发 ValueError 异常。 |
| recv() | 接收另一端通过 send() 方法发送过来的数据。 |
| close() | 关闭连接。 |
| poll([timeout]) | 返回连接中是否还有数据可以读取。 |
| send_bytes(buffer[, offset[, size]]) | 发送字节数据。如果没有指定 offset、size 参数,则默认发送 buffer 字节串的全部数据;如果指定了 offset 和 size 参数,则只发送 buffer 字节串中从 offset 开始、长度为 size 的字节数据。通过该方法发送的数据,应该使用 recv_bytes() 或 recv_bytes_into 方法接收。 |
| recv_bytes([maxlength]) | 接收通过 send_bytes() 方法发送的数据,maxlength 指定最多接收的字节数。该方法返回接收到的字节数据。 |
| recv_bytes_into(buffer[, offset]) | 功能与 recv_bytes() 方法类似,只是该方法将接收到的数据放在 buffer 中。 |
import multiprocessing
def processFun(conn, name):
print(multiprocessing.current_process().pid, '进程发送数据:', name)
conn.send(name)
if __name__ == "__main__":
# 创建管道
conn1, conn2 = multiprocessing.Pipe()
# 子进程
process = multiprocessing.Process(target=processFun,
args=(conn1, "http://forwardpeng/club/"))
# 启动
process.start()
process.join()
print(multiprocessing.current_process().pid, "接收数据:")
print(conn2.recv())
'''
3852 进程发送数据: http://forwardpeng/club/
3849 接收数据:
http://forwardpeng/club/
'''
Futures并发编程
多线程与单线程主要区别如下代码:
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)
函数ProcessPoolExecutor()表示创建进程池,使用多个进程并行的执行程序。不过,这里通常省略参数workers,因为系统会自动返回 CPU的数量作为可以调用的进程数。
但是,并行的方式一般用在CPU heavy的场景中,因为对于I/O heavy的操作,多数时间都会用于等待,相比于多线程,使用多进程并不会提升效率。反而很多时候,因为 CPU 数量的限制,会导致其执行效率不如多线程版本。
什么是Futures
Python Futures 模块,位于 concurrent.futures 和 asyncio 中,它们都表示带有延迟的操作。Futures 会将处于等待状态的操作包裹起来放到队列中,这些操作的状态随时可以查询,当然它们的结果(或是异常)也能够在操作完成后被获取。通常来说,用户不用考虑如何去创建 Futures,这些 Futures 底层都会帮我们处理好,唯一要做的只是去设定这些 Futures 的执行。比如,Futures 中的 Executor 类,当执行 executor.submit(func) 时,它便会安排里面的 func() 函数执行,并返回创建好的 future 实例,以便之后查询调用。
这里再介绍一些常用的函数。比如 Futures 中的方法 done(),表示相对应的操作是否完成,返回 True 表示完成;返回 False 表示没有完成。不过要注意的是,done() 是非阻塞的,会立即返回结果。相对应的 add_done_callback(fn),则表示 Futures 完成后,相对应的参数函数 fn 会被通知并执行调用。Futures 中还有一个重要的函数 result(),它表示当future完成后,返回其对应的结果或异常。而 as_completed(fs),则是针对给定的 future 迭代器 fs,在其完成后返回完成后的迭代器。
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
future = executor.submit(download_one, site)
to_do.append(future)
for future in concurrent.futures.as_completed(to_do):
future.result()
future 列表中每个 future 完成的顺序和它在列表中的顺序并不一定完全一致。到底哪个先完成、哪个后完成,取决于系统的调度和每个 future 的执行时间。
Asyncio并发编程
同步,是指操作一个接一个地执行,下一个操作必须等上一个操作执行完成之后才能开始执行;而异步是指不同操作间可以相互交替执行,如果其中地某个操作被堵塞,程序并不会等待,而是会找出可执行的操作继续执行。同步和异步的方式完成的过程如下:
- 如果按照同步的方式,应先向软件中输入各项数据,接下来等报表生成,再写邮件提交;
- 如果按照异步的方式,向软件中输出各项数据后,会先写邮件,等待报表生成后,暂停写邮件的工作去查看生成的报表,确认无误后在写邮件直到发送完毕。
Asyncio的原理
假设任务只有两个状态:,分别是预备状态和等待状态: - 预备状态是指任务目前空闲,但随时待命准备运行;
- 等待状态是指任务已经运行,但正在等待外部的操作完成,比如 I/O 操作。
事件循环会维护两个任务列表,分别对应这两种状态,并且选取预备状态的一个任务(具体选取哪个任务,和其等待的时间长短、占用的资源等等相关)使其运行,一直到这个任务把控制权交还给事件循环为止。
当任务把控制权交还给事件循环对象时,它会根据其是否完成把任务放到预备或等待状态的列表,然后遍历等待状态列表的任务,查看他们是否完成:如果完成,则将其放到预备状态的列表;反之,则继续放在等待状态的列表。而原先在预备状态列表的任务位置仍旧不变,因为它们还未运行。
这样,当所有任务被重新放置在合适的列表后,新一轮的循环又开始了,事件循环对象继续从预备状态的列表中选取一个任务使其执行…如此周而复始,直到所有任务完成。值得一提的是,对于 Asyncio 来说,它的任务在运行时不会被外部的一些因素打断,因此 Asyncio 内的操作不会出现竞争资源(多个线程同时使用同一资源)的情况,也就不需要担心线程安全的问题了。实现示例如下:
import asyncio
import aiohttp
import time
async def download_one(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
print('Read {} from {}'.format(resp.content_length, url))
async def download_all(sites):
tasks = [asyncio.ensure_future(download_one(site)) for site in sites]
await asyncio.gather(*tasks)
def main():
sites = [
'http://c.biancheng.net', 'http://c.biancheng.net/c',
'http://c.biancheng.net/python'
]
start_time = time.perf_counter()
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(download_all(sites))
finally:
loop.close()
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites),
end_time - start_time))
if __name__ == "__main__":
main()
'''
Read None from http://c.biancheng.net
Read None from http://c.biancheng.net/python
Read None from http://c.biancheng.net/c
Download 3 sites in 0.16684959100166452 seconds
'''
Async 和 await 关键字是 Asyncio 的最新写法,表示这个语句(函数)是非阻塞的,正好对应前面所讲的事件循环的概念,即如果任务执行的过程需要等待,则将其放入等待状态的列表中,然后继续执行预备状态列表里的任务。另外在主函数中,第 22-26 行代码表示拿到事件循环对象,并运行 download_all() 函数,直到其结束,最后关闭这个事件循环对象。和之前多线程版本有很大的区别:
- 这里的asyncio.ensure_future(coro) 表示对输入的协程 coro 创建一个任务,安排它的执行,并返回此任务对象。可以看到,这里对每一个网站的下载,都创建了一个对应的任务。
- asyncio.gather()表示在事件循环对象中运行aws序列的所有任务。
GIL全局解释器锁分析
实例如下:
import time
start = time.clock()
def CountDown(n):
while n > 0:
n -= 1
CountDown(100000)
print("Time used:", (time.clock() - start))
'''
Time used: 0.004934000000000001
'''
将上面的程序改写成多个线程如下:
import time
from threading import Thread
start = time.clock()
def CountDown(n):
while n > 0:
n -= 1
t1 = Thread(target=CountDown, args=[100000 // 2])
t2 = Thread(target=CountDown, args=[100000 // 2])
t1.start()
t2.start()
t1.join()
t2.join()
print("Time used:",(time.clock() - start))
'''
Time used: 0.005221000000000003
'''
运行效率非但没有提高,反而降低了。因为 GIL 限制了 Python 多线程的性能不会像我们预期的那样。
GIL是最流程的CPython解释器(平常称为 Python)中的一个技术术语,中文译为全局解释器锁,其本质上类似操作系统的Mutex。GIL的功能是:在CPython解释器中执行的每一个Python线程,都会先锁住自己,以阻止别的线程执行。当然,CPython不可能容忍一个线程一直独占解释器,它会轮流执行 Python 线程。这样一来,用户看到的就是“伪”并行,即 Python 线程在交替执行,来模拟真正并行的线程。
其实,这和 CPython 的底层内存管理有关。CPython使用引用计数来管理内容,所有Python脚本中创建的实例,都会配备一个引用计数,来记录有多少个指针来指向它。当实例的引用计数的值为0时,会自动释放其所占的内存。
>>> import sys
>>> a = []
>>> b = a
>>> sys.getrefcount(a)
3
# a的引用计数值为3,因为有 a、b 和作为参数传递的getrefcount都引用了一个空列表。
假设有两个Python线程同时引用a,那么双方就都会尝试操作该数据,很有可能造成引用计数的条件竞争,导致引用计数只增加1(实际应增加 2),这造成的后果是,当第一个线程结束时,会把引用计数减少1,此时可能已经达到释放内存的条件(引用计数为 0),当第2个线程再次视图访问a时,就无法找到有效的内存了。
GIL底层实现
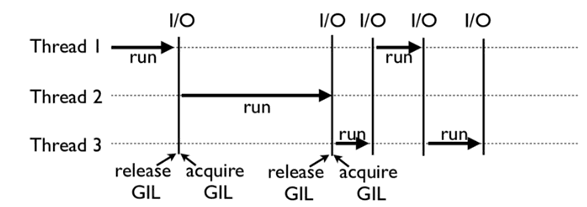
上图是GIL在Python程序的工作示例。其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放GIL,以允许别的线程开始利用资源。
Python线程在开始执行时锁住 GIL,且永远不去释放 GIL,那别的线程就都没有运行的机会。其实,CPython 中还有另一个机制,叫做间隔式检查(check_interval),意思是 CPython 解释器会去轮询检查线程 GIL 的锁住情况,每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。
//Python线程的循环封装
for (;;) {
if (--ticker < 0) {
ticker = check_interval;
/* Give another thread a chance */
PyThread_release_lock(interpreter_lock);
/* Other threads may run now */
PyThread_acquire_lock(interpreter_lock, 1);
}
bytecode = *next_instr++;
switch (bytecode) {
/* execute the next instruction ... */
}
}
// 每个Python线程都会先检查ticker计数。只有在ticker大于0的情况下,线程才会去执行自己的代码。
GIL不能绝对线程安全
有了 GIL,并不意味着 Python 程序员就不用去考虑线程安全了,因为即便 GIL 仅允许一个 Python 线程执行,但别忘了 Python 还有 check interval 这样的抢占机制。实例代码:
import threading
n = 0
def foo():
global n
n += 1
threads = []
for i in range(100):
t = threading.Thread(target=foo)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(n)
其大部分时候会打印100,但有时也会打印 99或者98,原因在于n+=1这一句代码让线程并不安全。
Python垃圾回收机制
Python程序在运行时,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量,计算完成后,再将结果输出到永久性存储器中。但是当数据量过大,或者内存空间管理不善,就很容易出现内存溢出的情况,程序可能会被操作系统终止。
引用计数机制
当这个对象的引用计数值为 0 时,说明这个对象永不再用,自然它就变成了垃圾,需要被回收。
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
'''
initial memory used: 8.90234375 MB
after a created memory used: 395.296875 MB
finished memory used: 9.21484375 MB
'''
# 在函数返回后,局部变量的引用会注销掉,此时列表 a 所指代对象的引用计数为 0,Python 便会执行垃圾回收,因此之前占用的大量内存就又回来了。
global a表示将a声明为全局变量,则即使函数返回后,列表的引用依然存在,于是a对象就不会被当做垃圾回收掉,依然占用大量内存。Python内部的引用计数机制实例2:
import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
'''
2
4
2
'''
手动垃圾回收需要先调用del a删除一个对象,然后强制调用gc.collect()启动垃圾回收。
循环引用
如果有两个对象,之间互相引用,且不再被别的对象所引用,导致引用数都不为0。示例:
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
'''
initial memory used: 8.90234375 MB
after a, b created memory used: 781.78125 MB
finished memory used: 781.79296875 MB
'''
Python 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。
先来看标记清除算法。我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在Python的垃圾回收实现中,标记清除算法使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。
分代收集算法,则是将Python中的所有对象分为三代。刚刚创立的对象是第0代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。事实上,分代收集基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高Python的性能。




