基本操作
常见的操作包括创建、删除、修改权限、读取、写入等,这些操作可大致分为以下 2 类:
- 删除、修改权限:作用于文件本身,属于系统级操作。
- 写入、读取:是文件最常用的操作,作用于文件的内容,属于应用级操作。
文件的应用级操作可以分为以下3步,每一步都需要借助对应的函数实现:
- 打开文件:使用 open()函数,该函数会返回一个文件对象;
- 对已打开文件做读/写操作:读取文件内容可使用read()、readline() 以及 readlines() 函数;向文件中写入内容,可以使用write()函数。
- 关闭文件:完成对文件的读/写操作之后,最后需要关闭文件,可以使用 close() 函数。
open()函数:打开指定文件
open()函数用于创建或打开指定文件,该函数的常用语法格式如下:
file = open(file_name [, mode=’r’ [ , buffering=-1 [ , encoding = None ]]])
此格式中,用[]括起来的部分为可选参数,即可以使用也可以省略。其中,各个参数所代表的含义如下:
- file:表示要创建的文件对象。
- file_mode:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
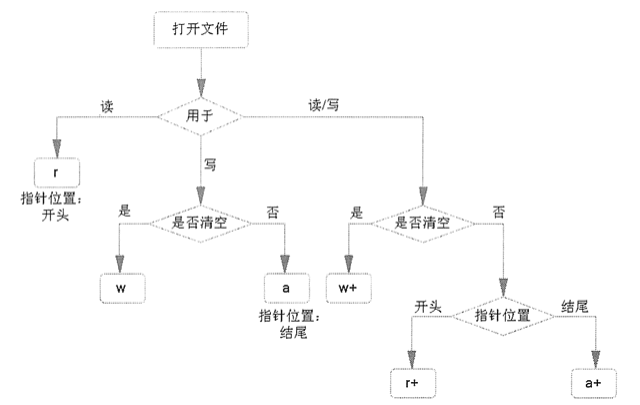
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。
buffing:可选参数,用于指定对文件做读写操作时,是否使用缓冲区(本节后续会详细介绍)。 - encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)
open()函数支持的文件打开模式如下表:
| 模式 | 意义 | 注意事项 |
| —— | ——————————————————————————————————————————————————————————————————————————— | ——————————————————————————————— |
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| rb | 以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。 | 操作的文件必须存在。 |
| r+ | 打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。 | 操作的文件必须存在。 |
| rb+ | 以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 | 操作的文件必须存在。 |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| wb | 以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 | | wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| |
| w+ | 打开文件后,会对原有内容进行清空,并对该文件有读写权限。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 | wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| |
| wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | |
| ab | 以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| a+ | 以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
| ab+ | 以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
文件打开模式,直接决定了后续可以对文件做哪些操作。例如,使用 r 模式打开的文件,后续编写的代码只能读取文件,而无法修改文件内容。
open()是否需要缓冲区
如果buffing参数的值为0(或者 False),则表示在打开指定文件时不使用缓冲区;如果buffing参数值为大于 1 的整数,该整数用于指定缓冲区的大小(单位是字节);如果buffing参数的值为负数,则代表使用默认的缓冲区大小。
使用缓冲区,则程序在执行输出操作时,会先将所有数据都输出到缓冲区中,然后继续执行其它操作,缓冲区中的数据会有外设自行读取处理;同样,当程序执行输入操作时,会先等外设将数据读入缓冲区中,无需同外设做同步读写操作。
open()文件对象常用的属性
成功打开文件之后,可以调用文件对象本身拥有的属性获取当前文件的部分信息,其常见的属性为:
- file.name:返回文件的名称;
- file.mode:返回打开文件时,采用的文件打开模式;
- file.encoding:返回打开文件时使用的编码格式;
- file.closed:判断文件是否己经关闭。
read()函数:按字节(字符)读取文件
Python 提供了如下 3 种函数,它们都可以帮我们实现读取文件中数据的操作:
- read() 函数:逐个字节或者字符读取文件中的内容;
- readline() 函数:逐行读取文件中的内容;
- readlines() 函数:一次性读取文件中多行内容。
read()函数
如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。read() 函数的基本语法格式如下:file.read([size])
其中,file表示已打开的文件对象;size 作为一个可选参数,用于指定一次最多可读取的字符(字节)个数,如果省略,则默认一次性读取所有内容。注意,当操作文件结束后,必须调用close() 函数手动将打开的文件进行关闭,这样可以避免程序发生不必要的错误。
readline()函数
readline() 函数用于读取文件中的一行,包含最后的换行符“\n”。此函数的基本语法格式为:
file.readline([size])
其中,file 为打开的文件对象;size 为可选参数,用于指定读取每一行时,一次最多读取的字符(字节)数。和read()函数一样,此函数成功读取文件数据的前提是,使用 open() 函数指定打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
由于 readline() 函数在读取文件中一行的内容时,会读取最后的换行符“\n”,再加上 print() 函数输出内容时默认会换行,所以输出结果中会看到多出了一个空行。
readlines()函数
readlines() 函数用于读取文件中的所有行,它和调用不指定 size 参数的 read() 函数类似,只不过该函数返回是一个字符串列表,其中每个元素为文件中的一行内容。和readline()函数一样,readlines()函数在读取每一行时,会连同行尾的换行符一块读取。readlines()函数的基本语法格式如下:
file.readlines()
其中,file 为打开的文件对象。和 read()、readline() 函数一样,它要求打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
write()和writelines():向文件中写入数据
Python 中的文件对象提供了 write() 函数,可以向文件中写入指定内容。该函数的语法格式如下:
file.write(string)
其中,file 表示已经打开的文件对象;string 表示要写入文件的字符串(或字节串,仅适用写入二进制文件中)。
注意,在使用 write() 向文件中写入数据,需保证使用 open() 函数是以 r+、w、w+、a 或 a+ 的模式打开文件,否则执行 write() 函数会抛出 io.UnsupportedOperation 错误。采用不同的文件打开模式,会直接影响 write() 函数向文件中写入数据的效果。
另外,在写入文件完成后,一定要调用 close() 函数将打开的文件关闭,否则写入的内容不会保存到文件中。例如,将上面程序中最后一行 f.close() 删掉,再次运行此程序并打开 a.txt,你会发现该文件是空的。这是因为,当我们在写入文件内容时,操作系统不会立刻把数据写入磁盘,而是先缓存起来,只有调用 close() 函数时,操作系统才会保证把没有写入的数据全部写入磁盘文件中。
writelines()函数
Python 的文件对象中,不仅提供了 write() 函数,还提供了 writelines() 函数,可以实现将字符串列表写入文件中。注意,写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
f = open('a.txt', 'r')
n = open('b.txt','w+')
n.writelines(f.readlines())
n.close()
f.close()
使用 writelines()函数向文件中写入多行数据时,不会自动给各行添加换行符。上面例子中,之所以b.txt文件中会逐行显示数据,是因为readlines()函数在读取各行数据时,读入了行尾的换行符。
colse()函数
Python 出于效率的考虑,会先将数据临时存储到缓冲区中,只有使用close()函数关闭文件时,才会将缓冲区中的数据真正写入文件中。语法格式:
file.close()
当然在某些实际场景中,我们可能需要在将数据成功写入到文件中,但并不想关闭文件。这也是可以实现的,调用 flush() 函数即可。
tell()函数
当向文件中写入数据时,如果不是文件的尾部,写入位置的原有数据不会自行向后移动,新写入的数据会将文件中处于该位置的数据直接覆盖掉。基本语法为:
file.tell()
# a.txt: http://forwardpeng.club f = open("a.txt", 'r') print(f.tell()) print(f.read(3)) print(f.tell()) ''' 0 htt 3 '''seek()函数
seek()函数用于将文件指针移动至指定位置,该函数的语法格式如下:
file.seek(offset[, whence])
其中,各个参数的含义如下:
- file:表示文件对象;
- whence:作为可选参数,用于指定文件指针要放置的位置,该参数的参数值有 3 个选择:0 代表文件头(默认值)、1 代表当前位置、2 代表文件尾。
- offset:表示相对于 whence 位置文件指针的偏移量,正数表示向后偏移,负数表示向前偏移。例如,当whence == 0 &&offset == 3(即 seek(3,0) ),表示文件指针移动至距离文件开头处 3 个字符的位置;当whence == 1 &&offset == 5(即 seek(5,1) ),表示文件指针向后移动,移动至距离当前位置 5 个字符处。
注意,当 offset 值非 0 时,Python 要求文件必须要以二进制格式打开,否则会抛出 io.UnsupportedOperation 错误。
pickle模块:实现对象持久化存储
pickle 模块提供了以下 4 个函数供我们使用:
- dumps():将 Python 中的对象序列化成二进制对象,并返回;
- loads():读取给定的二进制对象数据,并将其转换为 Python 对象;
- dump():将 Python 中的对象序列化成二进制对象,并写入文件;
- load():读取指定的序列化数据文件,并返回对象。
以上这4个函数可以分成两类,其中 dumps 和 loads 实现基于内存的 Python 对象与二进制互转;dump 和 load 实现基于文件的 Python 对象与二进制互转。
pickle.dumps()函数
用于将 Python 对象转为二进制对象,其语法格式如下:
dumps(obj, protocol=None, *, fix_imports=True)
此格式中各个参数的含义为:
- obj:要转换的 Python 对象;
- protocol:pickle 的转码协议,取值为 0、1、2、3、4,其中 0、1、2 对应 Python 早期的版本,3 和 4 则对应 Python 3.x 版本及之后的版本。未指定情况下,默认为 3。
- 其它参数:为了兼容 Python 2.x 版本而保留的参数,Python 3.x 中可以忽略。
pickle.loads()函数
用于将二进制对象转换成 Python 对象,其基本格式如下:loads(data, *, fix_imports=True, encoding=’ASCII’, errors=’strict’)
其中,data 参数表示要转换的二进制对象,其它参数只是为了兼容Python 2.x版本而保留的,可以忽略。
pickle.dump()
用于将 Python 对象转换成二进制文件,其基本语法格式为:
dump (obj, file,protocol=None, *, fix mports=True)
其中各个参数的具体含义如下:
- obj:要转换的 Python 对象。
- file:转换到指定的二进制文件中,要求该文件必须是以”wb”的打开方式进行操作。
- protocol:和 dumps() 函数中 protocol 参数的含义完全相同,因此这里不再重复描述。
pickle.load()函数
用于将二进制对象文件转换成 Python 对象。该函数的基本语法格式为:
load(file, *, fix_imports=True, encoding=’ASCII’, errors=’strict’)
其中,file参数表示要转换的二进制对象文件(必须以 “rb” 的打开方式操作文件)。
pickle 不支持并发地访问持久性对象,在复杂的系统环境下,尤其是读取海量数据时,使用 pickle 会使整个系统的I/O读取性能成为瓶颈。这种情况下,可以使用 ZODB。
fileinput模块:逐行读取多个文件
fileinput 模块中 input() 该函数的语法格式如下:
fileinput.input(files=”filename1, filename2, …”, inplace=False, backup=’’, bufsize=0, mode=’r’, openhook=None)
此函数会返回一个 FileInput 对象,它可以理解为是将多个指定文件合并之后的文件对象。其中,各个参数的含义如下:
- files:多个文件的路径列表;
- inplace:用于指定是否将标准输出的结果写回到文件,此参数默认值为 False;
- backup:用于指定备份文件的扩展名;
- bufsize:指定缓冲区的大小,默认为 0;
- mode:打开文件的格式,默认为 r(只读格式);
- openhook:控制文件的打开方式,例如编码格式等。
fileinput模块常见函数如下表:
| 函数名 | 功能描述 |
| ———————————- | ———————————————————————- |
| fileinput.filename() | 返回当前正在读取的文件名称。 |
| fileinput.fileno() | 返回当前正在读取文件的文件描述符。 |
| fileinput.lineno() | 返回当前读取了多少行。 |
| fileinput.filelineno() | 返回当前正在读取的内容位于当前文件中的行号。 |
| fileinput.isfirstline() | 判断当前读取的内容在当前文件中是否位于第 1 行。 |
| fileinput.nextfile() | 关闭当前正在读取的文件,并开始读取下一个文件。 |
| fileinput.close() | 关闭 FileInput 对象。 |
linecache模块:读取指定行
linecache模块擅长读取指定文件中的指定行。换句话说,如果我们想读取某个文件中指定行包含的数据,就可以使用 linecache模块。inecache 模块中常用的函数及其功能如下表所示。
| 函数基本格式 | 功能 |
| ———————————————————————————— | —————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————- |
| linecache.getline(filename, lineno, module_globals=None) | 读取指定模块中指定文件的指定行(仅读取指定文件时,无需指定模块)。其中,filename 参数用来指定文件名,lineno 用来指定行号,module_globals 参数用来指定要读取的具体模块名。注意,当指定文件以相对路径的方式传给 filename 参数时,该函数以按照 sys.path 规定的路径查找该文件。 |
| linecache.clearcache() | 如果程序某处,不再需要之前使用 getline() 函数读取的数据,则可以使用该函数清空缓存。 |
| linecache.checkcache | (filename=None) 检查缓存的有效性,即如果使用 getline() 函数读取的数据,其实在本地已经被修改,而我们需要的是新的数据,此时就可以使用该函数检查缓存的是否为新的数据。注意,如果省略文件名,该函数将检车所有缓存数据的有效性。 |
os.path模块常见函数
| 方法 | 说明 |
|---|---|
| os.path.abspath(path) | 返回 path 的绝对路径。 |
| os.path.basename(path) | 获取 path 路径的基本名称,即 path 末尾到最后一个斜杠的位置之间的字符串。 |
| os.path.commonprefix(list) | 返回 list(多个路径)中,所有 path 共有的最长的路径。 |
| os.path.dirname(path) | 返回 path 路径中的目录部分。 |
| os.path.exists(path) | 判断 path 对应的文件是否存在,如果存在,返回 True;反之,返回 False。和 lexists() 的区别在于,exists()会自动判断失效的文件链接(类似 Windows 系统中文件的快捷方式),而 lexists() 却不会。 |
| os.path.lexists(path) | 判断路径是否存在,如果存在,则返回 True;反之,返回 False。 |
| os.path.expanduser(path) | 把 path 中包含的 “~” 和 “~user” 转换成用户目录。 |
| os.path.expandvars(path) | 根据环境变量的值替换 path 中包含的 “$name” 和 “${name}”。 |
| os.path.getatime(path) | 返回 path 所指文件的最近访问时间(浮点型秒数)。 |
| os.path.getmtime(path) | 返回文件的最近修改时间(单位为秒)。 |
| os.path.getctime(path) | 返回文件的创建时间(单位为秒,自 1970 年 1 月 1 日起(又称 Unix 时间))。 |
| os.path.getsize(path) | 返回文件大小,如果文件不存在就返回错误。 |
| os.path.isabs(path) | 判断是否为绝对路径。 |
| os.path.isfile(path) | 判断路径是否为文件。 |
| os.path.isdir(path) | 判断路径是否为目录。 |
| os.path.islink(path) | 判断路径是否为链接文件(类似 Windows 系统中的快捷方式)。 |
| os.path.ismount(path) | 判断路径是否为挂载点。 |
| os.path.join(path1[, path2[, …]]) | 把目录和文件名合成一个路径。 |
| os.path.normcase(path) | 转换 path 的大小写和斜杠。 |
| os.path.normpath(path) | 规范 path 字符串形式。 |
| os.path.realpath(path) | 返回 path 的真实路径。 |
| os.path.relpath(path[, start]) | 从 start 开始计算相对路径。 |
| os.path.samefile(path1, path2) | 判断目录或文件是否相同。 |
| os.path.sameopenfile(fp1, fp2) | 判断 fp1 和 fp2 是否指向同一文件。 |
| os.path.samestat(stat1, stat2) | 判断 stat1 和 stat2 是否指向同一个文件。 |
| os.path.split(path) | 把路径分割成 dirname 和 basename,返回一个元组。 |
| os.path.splitdrive(path) | 一般用在 windows 下,返回驱动器名和路径组成的元组。 |
| os.path.splitext(path) | 分割路径,返回路径名和文件扩展名的元组。 |
| os.path.splitunc(path) | 把路径分割为加载点与文件。 |
| os.path.walk(path, visit, arg) | 遍历path,进入每个目录都调用 visit 函数,visit 函数必须有 3 个参数(arg, dirname, names),dirname 表示当前目录的目录名,names 代表当前目录下的所有文件名,args 则为 walk 的第三个参数。 |
| os.path.supports_unicode_filenames | 设置是否可以将任意 Unicode 字符串用作文件名。 |
fnmatch模块:用于文件名匹配
fnmatch模块中,常用的函数及功能如下表:
| 函数名 | 功能 |
| ——————————————————— | —————————————————————————————————————- |
| fnmatch.filter(names, pattern) | 对 names 列表进行过滤,返回 names 列表中匹配 pattern 的文件名组成的子集合。 |
| fnmatch.fnmatch(filename, pattern) | 判断 filename 文件名,是否和指定 pattern 字符串匹配 |
| fnmatch.fnmatchcase(filename, pattern) | 和 fnmatch() 函数功能大致相同,只是该函数区分大小写。 |
| fnmatch.translate(pattern) | 将一个UNIX shell风格的pattern字符串,转换为正则表达式 |
fnmatch 模块匹配文件名的模式使用的就是 UNIX shell 风格,其支持使用如下几个通配符:
- *:可匹配任意个任意字符。
- ?:可匹配一个任意字符。
- [字符序列]:可匹配中括号里字符序列中的任意字符。该字符序列也支持中画线表示法。比如 [a-c] 可代表 a、b 和 c 字符中任意一个。
- [!字符序列]:可匹配不在中括号里字符序列中的任意字符。
tempfile模块:生成临时文件和临时目录
| tempfile 模块函数 | 功能描述 |
|---|---|
| tempfile.TemporaryFile(mode=’w+b’, buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None) | 创建临时文件。该函数返回一个类文件对象,也就是支持文件 I/O。 |
| tempfile.NamedTemporaryFile(mode=’w+b’, buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None, delete=True) | 创建临时文件。该函数的功能与上一个函数的功能大致相同,只是它生成的临时文件在文件系统中有文件名。 |
| tempfile.SpooledTemporaryFile(max_size=0, mode=’w+b’, buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None) | 创建临时文件。与 TemporaryFile 函数相比,当程序向该临时文件输出数据时,会先输出到内存中,直到超过 max_size 才会真正输出到物理磁盘中。 |
| tempfile.TemporaryDirectory(suffix=None, prefix=None, dir=None) | 生成临时目录。 |
| tempfile.gettempdir() | 获取系统的临时目录。 |
| tempfile.gettempdirb() | 与 gettempdir() 相同,只是该函数返回字节串。 |
| tempfile.gettempprefix() | 返回用于生成临时文件的前缀名。 |
| tempfile.gettempprefixb() | 与 gettempprefix() 相同,只是该函数返回字节串。 |
创建临时文件的方法:
- 第一种方式是手动创建临时文件,读写临时文件后需要主动关闭它,当程序关闭该临时文件时,该文件会被自动删除。
- 第二种方式则是使用 with 语句创建临时文件,这样 with 语句会自动关闭临时文件。




